人类大脑作为自然界中最神秘、最复杂的信息处理系统,包含了约860亿个神经元,这些神经元之间又有着超过100万亿个突触连接。了解大脑的动态可塑性和巨大复杂的网络结构,弄清智能发生的机理,借鉴生物智能实现人工智能的突破仍然面临巨大挑战。
数字孪生脑的问世,为解决这一难题提供了一个全新的视角和方法。它利用和借鉴数字孪生技术,通过逆向工程技术构建生物大脑的数字副本,“破译”脑在信息处理与神经编码原理的方式,实现从结构仿脑到功能仿脑。2023年底,美国国家科学院发布了关于发展数字孪生的整本白皮书, 其中关于数字孪生脑的研究内容就占了1/3,提出了从人脑实验数据结合方式来验证和研究大脑智能的机理。欧共体也在人脑计划结束之后启动了EBRAIN, 并于2024年开始了一千万欧元资助的虚拟脑孪生的项目。
近期,复旦大学计算神经科学与类脑智能教育部重点实验室冯建峰教授研究团队发布了数字孪生脑(Digital Twin Brain:DTB)平台,这是国际上首个基于数据同化方法开发的具备860亿神经元规模、百万亿突触的全人脑尺度大脑模拟平台。通过平台研究工作发现,数字孪生脑在规模与结构上越接近人类大脑,会逐渐展现出类似在人脑中观测到的临界现象与相似的认知功能。该研究成果以《类脑计算模拟和探索人类大脑的静息和任务状态:尺度与结构》“Imitating and exploring human brain's resting and task-performing states via resembling brain computing: scaling and architecture”为题,发表在《国家科学评论》(National Science Review, NSR)。该文将作为封面文章收录于NSR“人类大脑计算与类脑智能”专题。
数字孪生脑示意图:通过计算系统模拟生物大脑的结构与功能
成年人全脑包括至少860亿神经元、百万亿神经突触,而自然语言大模型GPT3和GPT4的参数量在千亿规模,如何从少量数据(比如MRI、EEG、MEG等)确定如此大规模的模型,是利用全脑模型与数据结合的难点。团队发展的多层数据同化方法,为大脑大模型的估计与辨识提供有效的技术手段,通过介观尺度的统计,推断具有人类大脑规模的脉冲神经元网络模型。
全脑模型具有“大规模”与“真实生物结构”,通过构建人类大脑计算模型,并将同化后数字孪生脑与实验采集的静息态与认知实验任务态的BOLD数据进行比较发现,数字孪生脑与真实大脑在规模尺度和连接结构上越相似,它模拟出的数据与生物脑活动的实验记录在静息状态和任务过程的相似匹配度越高,并且越接近展现出临界现象。而大脑处于临界态被猜想是大脑功能相关的重要时空动力学特征。
数字脑在50亿神经元规模(相当于猕猴大脑神经元规模)的大模型上,会逐渐展现出类似在人脑中观测到的临界现象与相似的认知功能。目前,团队已经完成了860亿神经元、总突触47.8万亿的全脑模型的形态模拟计算。
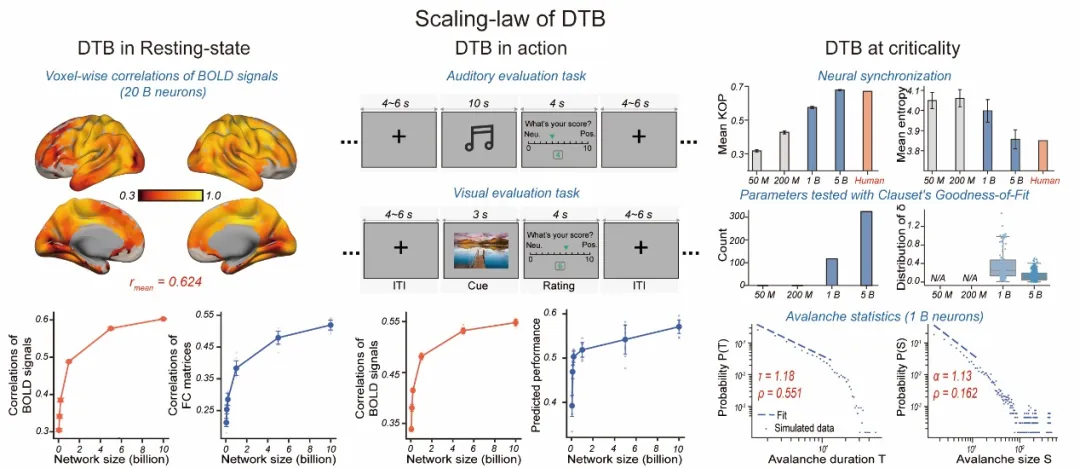
对于数字孪生脑的应用前景,冯建峰介绍道:“数字孪生脑平台可帮助脑科学家进行数字实验,探索和验证神经科学理论、大脑智能机理”。如团队利用数字孪生脑进行的数字损伤实验时,在模型中切断了初级视觉皮层(V1)到下游视觉途径的连接移除会显著降低数字脑模型与真实大脑在海马中的相似性,发现对整个大脑的影响很小。数字孪生脑还可以用来开展无生物主体时的“干”实验,研究团队通过设计“丘脑”信息驱动与“内感知”信息驱动的HAD实验范式,来测试静息状态下脑活动反映了内部身体状态的假设,发现内感知回路的信息驱动范式显著增强了模型与生物大脑之间的相似性。
更进一步,冯建峰教授展望道:“这是我们数字孪生脑平台构建工作迈开的第一步,为探究大脑结构与相应高级认知功能的复杂关系提供了一个研究实例。数字化模拟真实大脑是实现理解大脑工作原理、启发未来通用人工智能的有效途径之一。我们研究中遇到的问题,都代表着模拟脑在计算硬件、系统以及计算方法领域的严峻挑战, 是未来长期研究的焦点。
原文链接:https://doi.org/10.1093/nsr/nwae080


